製品
アクセラレータ
エージェント カタログ
パートナー ソリューション
プロフェッショナル サービス
コレクション
サインイン
製品
アクセラレータ
エージェント カタログ
パートナー ソリューション
プロフェッショナル サービス
コレクション
はじめてのオートメーションをわずか数分で作成できます。Studio Web を試す →

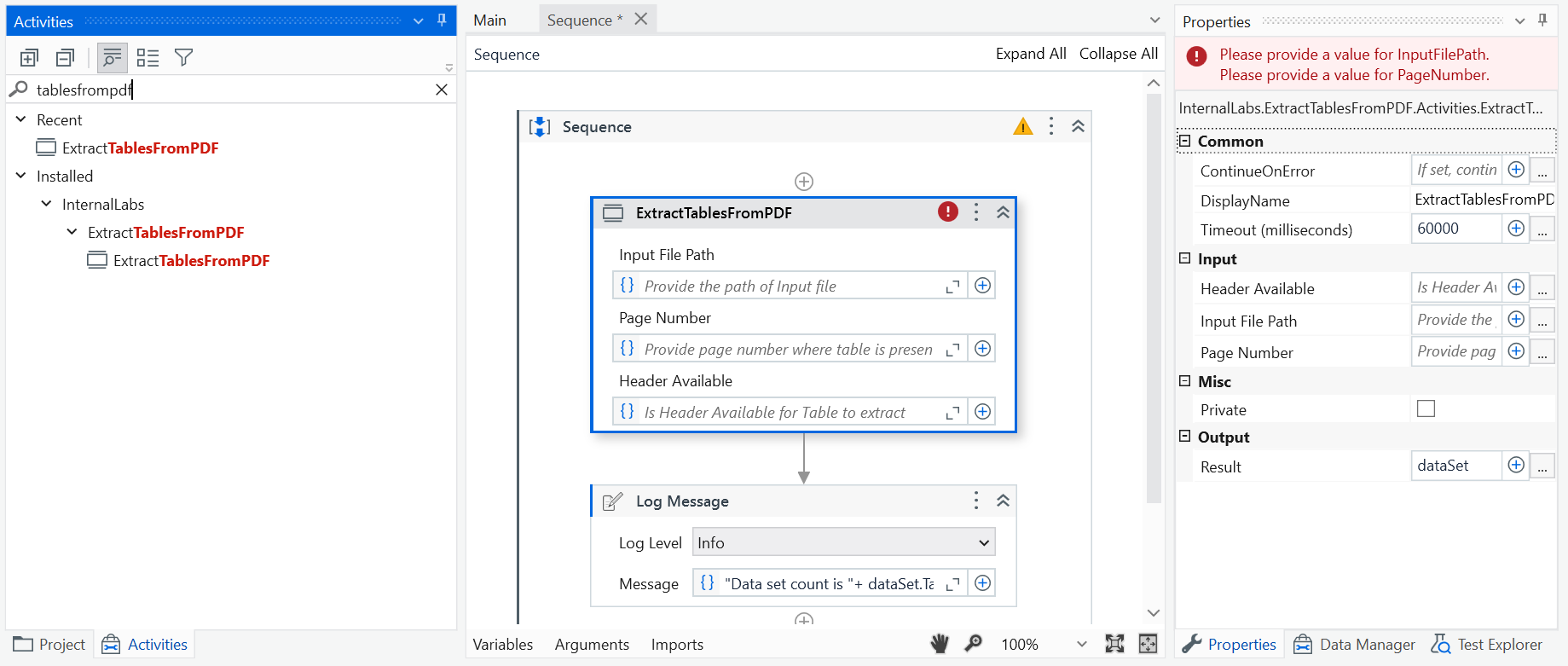
Extract Tables from PDF
作成者: Internal Labs
2
アクティビティ
258
要約
要約
Extract the table(s) from a PDF file.
概要
概要
This package contains one activity that helps users to extract the table(s) from a PDF file.
Mandatory input fields:
- Header Available - Is Header available for the table to be extracted.
- Input File Path - Provide the path of the Input file.
- Page Number - Provide the page number where the table(s) are present in the PDF file.
Note: The PDF file path should be the absolute path.
The activity only supports native PDF/text-based PDFs, not scanned documents.
機能
機能
This activity helps users to extract the table(s) from a PDF file, eliminating the manual work involved for this task.
その他の情報
その他の情報
依存関係
Pdfpig, tabula-sharp
コード言語
Visual Basic
ランタイム
Windows (.NET 5.0 以上)





