Sign In
Create your first automation in just a few minutes.Try Studio Web →
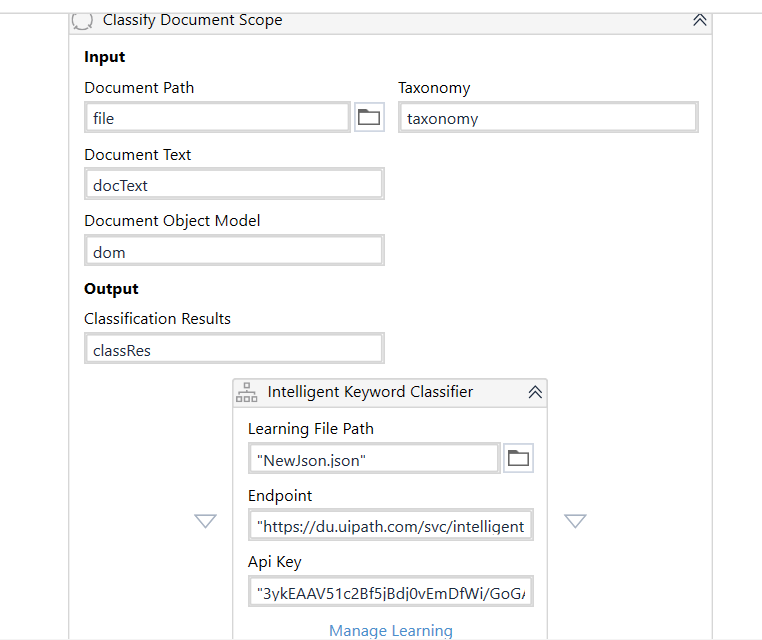
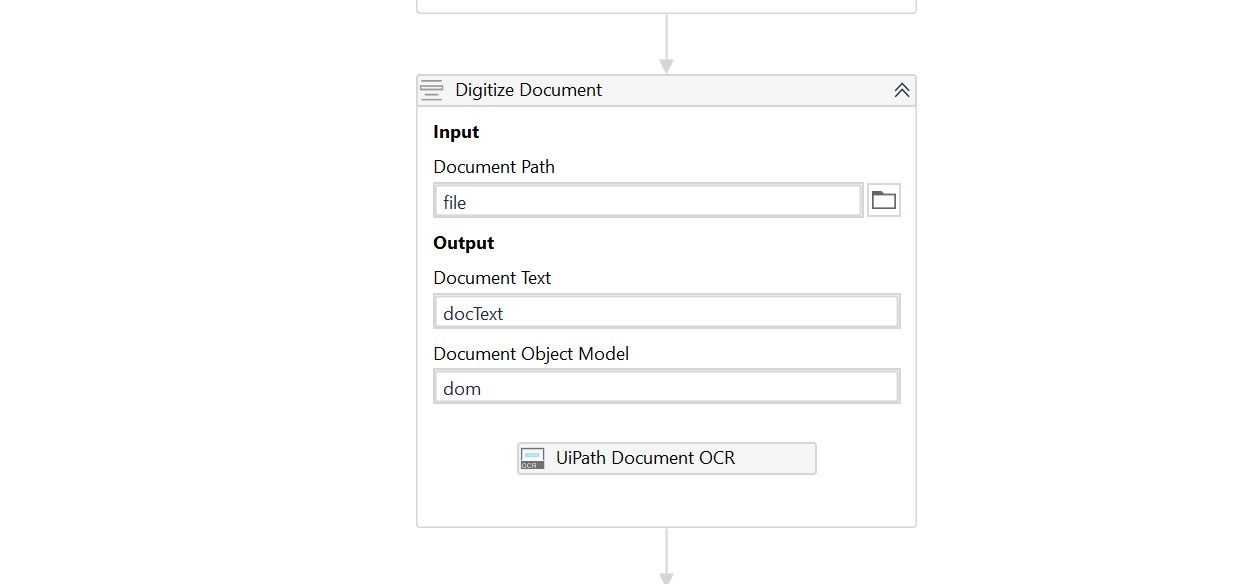
Acord Form & Unique Document Data Extraction
by ValueMomentum Inc.
1
Solution
<100
Summary
Summary
Extract the data from unique structured, semi-structured and unstructured Acord forms, schedules, loss runs etc. that are printed – PDF files or scanned images and hand-written documents.
Overview
Overview
Acord Form & other unique document types data extraction by using Intelligent Document Understanding functionality.
Extracting varied data from different types of documents is a key challenge and a monotonous time-consuming activity for insurers, as the pattern and format of such documents appear unique, which is a cumbersome task of not being able to extract the data from these documents quickly. The documents that need to be processed are either structured, unstructured, and semi-structured Acord forms, schedules, loss runs and so on.
Since the amount of data to be extracted from these set of documents is varied, it becomes a difficult task to understand the importance of data to be extracted as well as to process multiple documents in a single go that are typically received as email attachments during a new business submission or claims intake process.
This solution is useful for extracting these unique data from multiple document types and formats that may be printed, scanned images or hand-written. By using the intelligent document understanding functionality, it becomes simpler to identify and understand the data elements and data types that need to be extracted from different intake document types.
Features
Features
1. Reduce submission intake processing time by 30 – 40% and respond to brokers/agents faster.
2. Enhance operations teams productivity by enabling to increase the daily transaction processing count by 20%.
3. Reducing the new submission and claims intake processing cost by 25 – 30%.
4. Improve processing accuracy and eliminate process leakages, re-work/errors.
Additional Information
Additional Information
Dependencies
1.UiPath.IntelligentOCR.Activities 2.UiPath.MachineLearningExtractor 3.UiPath.OmniPage.Activities
Code Language
Visual Basic
License & Privacy
Apache
Privacy Terms
Technical
Version
1.0.1Updated
December 14, 2021Works with
Studio: 21.10 - 22.10
Certification
Silver Certified
Application
Support
Phone: +
Email: uipath@valuemomentum.com
3 business days
Resources