Sign In
Create your first automation in just a few minutes.Try Studio Web →
The Dice Coefficient - String Matching Algorithm
by Internal Labs
0
Snippet
<100
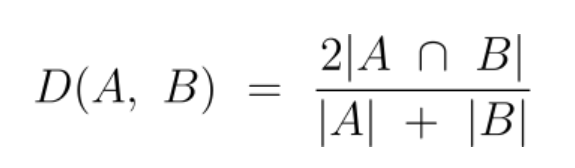
Summary
Summary
The Dice Coefficient algorithm/Sørensen-Dice coefficient, is commonly used for comparing the similarity between two strings and provides the matching percentage ranges from 0 to 1.
Overview
Overview
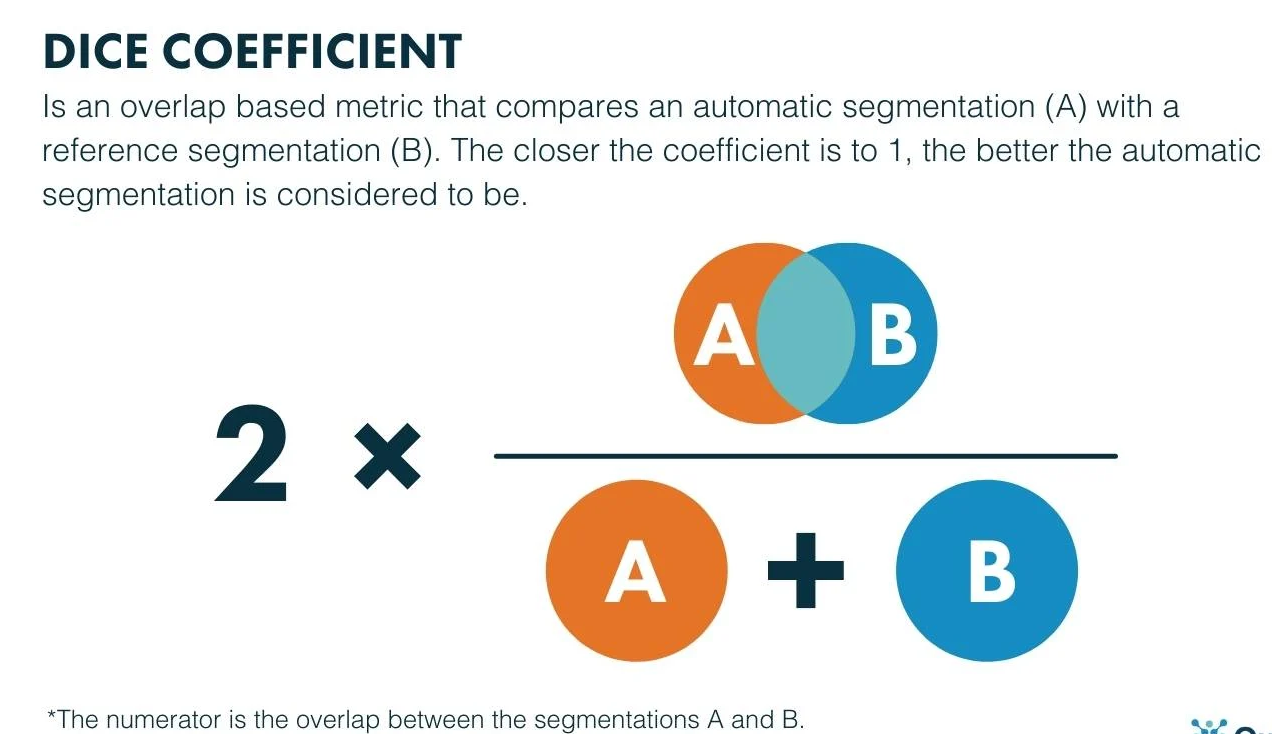
The Dice Coefficient (also known as the Sørensen-Dice coefficient) is a statistical measure used to evaluate the similarity between two sets of data. It is primarily used for comparing the similarity of text strings or other sequences in areas like natural language processing, image analysis, and data comparison. The Dice Coefficient ranges from 0 to 1, where:
- 0 indicates no similarity (completely different sets).
- 1 indicates a perfect match (identical sets).
Formula:
For two sets AAA and BBB, the Dice Coefficient is calculated as:
Dice Coefficient=2×∣A∩B∣∣A∣+∣B∣\text{Dice Coefficient} = \frac{2 \times |A \cap B|}{|A| + |B|}Dice Coefficient=∣A∣+∣B∣2×∣A∩B∣
Where:
- ∣A∩B∣|A \cap B|∣A∩B∣ is the number of elements common to both sets AAA and BBB.
- ∣A∣|A|∣A∣ and ∣B∣|B|∣B∣ are the sizes of sets AAA and BBB, respectively.
In the context of text comparison:
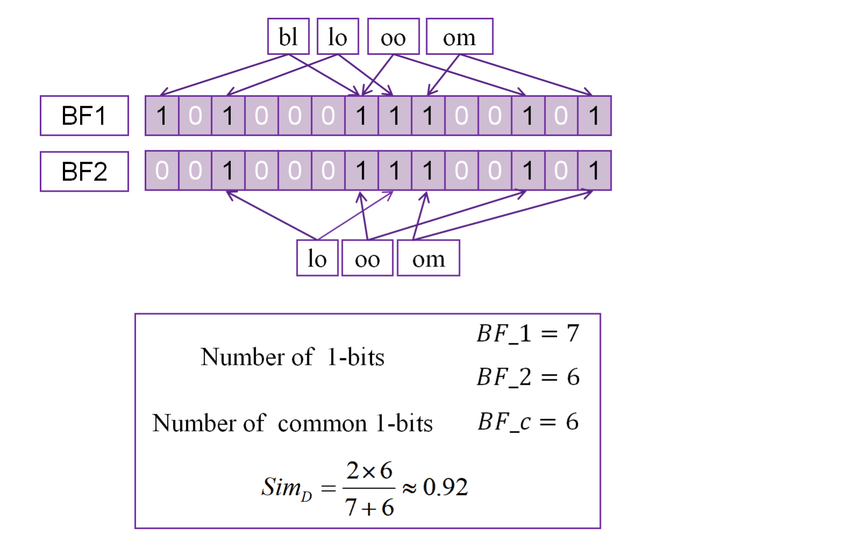
- The sets AAA and BBB are typically tokenized (split) strings, often into bigrams (pairs of consecutive characters or words).
- The Dice Coefficient calculates how many bigrams overlap between two strings, measuring their similarity.
Example:
For two strings "night" and "nacht":
- Bigram representation of "night": {"ni", "ig", "gh", "ht"}
- Bigram representation of "nacht": {"na", "ac", "ch", "ht"}
Their Dice Coefficient would be calculated by counting the overlapping bigrams ("ht") and applying the formula.
Applications:
- Text similarity: Comparing documents, names, or other strings to identify how closely they match.
- Image processing: Comparing the similarity of two image regions.
- Biology: Comparing sets of genes or proteins.
The Dice Coefficient is particularly useful for situations where exact matches are not required, but a degree of similarity is important.
Features
Features
Dice Coefficient Calculation:
- Implements the Sørensen-Dice similarity algorithm to compare the similarity between two text strings or arrays.
- Can handle text comparisons by breaking down strings into character n-grams or word tokens.
UiPath Integration:
- Fully integrated into UiPath workflows, allowing easy implementation within robotic process automation (RPA) tasks.
- Workflow provided for direct use within UiPath Studio for both string comparison and set-based operations.
- Accepts input parameters for two strings or datasets and returns the similarity score as a
Double.
String Preprocessing:
- Built-in string preprocessing features like lowercasing, trimming, and optional removal of punctuation for more accurate comparisons.
- Configurable tokenization options to split strings by characters or words.
Error Handling:
- Implements robust error handling within the workflow, ensuring that null or invalid inputs do not cause workflow failures.
- Logs detailed error messages for debugging purposes.
Additional Information
Additional Information
Dependencies
UiPath.System.Activities: 23.10.2
Code Language
Visual Basic
Technical
Version
1.0.0Updated
November 18, 2024
Works with
Studio: 22.10.12 - 24.10.5
Certification
Silver Certified
Application
Support
UiPath Community Support
Resources